Linked Data
Winter 2019
Instructor: Raghava Mutharaju
IIIT-Delhi

Introduction
- Individual data silos
- Intra and inter connected/linked data
- Links are typed: relation between two entities can be indicated
- Huge amount of data is generated continuously
- How can data be reused easily?
- How can we enable discovery of relevant data?
- How can we enable applications to integrate data from multiple sources?
- Linked Data helps in discovering, accessing, integrating, and using data
- WWW helps in connecting and consuming documents. Through Linked Data, it can also help in connecting and consuming data
- Rationale for Linked Data
- Structured data enables sophisticated processing
- Hyperlinks connect distributed data
- Makes the data discoverable
- From data islands to a global data space
- RDF links things, not just documents
- RDF links are typed
- Web of Data (analogous to Web of documents)
Linked Open Data Cloud
https://lod-cloud.net/
Principles of Linked Data
- Linked Data refers to a set of best practices/principles for publishing and interlinking structured data on the Web
- These principles were introduced by Tim Berners-Lee
- Linked Data principles
- Use URIs as names for things
- Use HTTP URIs, so that people can look up those names (make URIs dereferenceable)
- When someone looks up a URI, provide useful information, using the standards (RDF, SPARQL)
- Include links to other URIs, so that they can discover more things
Naming Things using URIs
- Resources (real-world entities, abstract concepts) need to be uniquely identified
- HTTP URIs is a good mechanism to identify resources
- They provide a simple mechanism to create globally unique identifiers
- They provide a means of accessing the identified entity
Make URIs Defererenceable
- HTTP clients can look up the URI and retrieve the resource's description
- Content negotiation
- HTTP clients can include in their headers what type of description they are looking for
- HTML description is for human consumption
- RDF description is for machine consumption
- Two strategies can be used make URIs: 303 URIs and Hash URIs
Make URIs Defererenceable
- 303 URIs
- Client performs a HTTP GET on a URI. It indicates either Accept: application/rdf+xml or Accept: text/html in the header
- Server responds with a HTTP 303 See Other response that includes the URI of the resource in requested format
- Client performs HTTP GET on this URI
- Server responds with the document and 200 OK
Make URIs Defererenceable
- Hash URIs
- 303 URIs requires two HTTP requests. Hash URIs avoids that.
- URIs can have a base part and a fragment identifier (after #)
- http://biglynx.co.uk/vocab/sme#Team
- Client removes the fragment identifier (HTTP protocol requirement) and sends rest of the URI to the server
- Server returns the details of all the fragment identifiers
- So client might end up with large number of triples that it is not interested in
Provide Useful RDF Information
- When publishing Linked Data on the Web, data is represented in the form of RDF
- The two most commonly used serialization formats when publishing Linked Data are rdf/xml and RDFa
- RDF features that should be best avoided when publishing Linked Data
- RDF reification: querying becomes cumbersome
- RDF collections: querying becomes cumbersome
- Blank nodes: they have local scope
Include Links to Other Things
- Include external RDF links to other data sources so that data islands can be transformed into global, interconnected data space
- There are three important types of RDF links
- Relationship Links: they point to related things in other data sources
- Identity Links: they point to URI aliases
- Vocabulary Links: they point to the definition of vocabulary terms that are used to represent the data
Summary
- A unifying data model: RDF
- A standardized data access mechanism: HTTP
- Hyperlink-based data discovery: URIs
- Self-descriptive data: shared vocabularies and data descriptions
5 Star Rating Scheme
- One Star: data is available on the web (whatever format), but with an open license
- Two Stars: data is available as machine-readable structured data (e.g., Microsoft Excel instead of a scanned image of a table)
- Three Stars: data is available as (2) but in a non-proprietary format (e.g., CSV instead of Excel)
- Four Stars: data is available according to all the above, plus the use of open standards from the W3C (RDF and SPARQL) to identify things, so that people can link to it
- Five Stars: data is available according to all the above, plus outgoing links to other people’s data to provide context
Publishing Data about Data
- Two common mechanisms to describe data are Semantic Sitemaps and voiD descriptions
- Semantic Sitemaps: similar to sitemap (url,loc,lastmod,changefreq), but has more elements such as location of data dumps, SPARQL endpoints
- voiD: stands for Vocabulary of Interlinked Data. It is similar to Semantic Sitemap, except that it is in RDF. Subsets of a dataset can also be defined and linked to other datasets
Using Vocabularies to Describe Data
- There are several popular existing vocabularies that can be reused to describe data, rather than reinventing the terms
- If existing vocabularies are used then there is a higher chance that your data will be consumed/understood by applications
- Dublin Core: defines general metadata attributes such as title, creator, date and subject
- Friend-of-a-Friend (FOAF): defines terms for describing persons, their activities and their relations to other people and objects
- schema.org: created by major search engines to discover data for search
- SKOS: bridge between different knowledge organization systems (thesaurus, taxonomy) to Semantic Web standards (RDF, OWL)
- Semantically-Interlinked Online Communities (SIOC): designed for describing aspects of online community sites, such as users, posts and forums
- Description of a Project (DOAP): defines terms for describing software projects, particularly those that are Open Source
- Good Relations Ontology: defines terms for describing products, services and other aspects relevant to e-commerce applications
- Creative Commons (CC): defines terms for describing copyright licenses in RDF
- Review Vocabulary: vocabulary for representing reviews and ratings, as are often applied to products and services
- Programmes Ontology: defines terms for describing programmes such as TV and radio broadcasts
- Basic Geo (WGS84): defines terms such as lat and long for describing geographically-located things
- Music Ontology: defines terms for describing various aspects related to music, such as artists, albums, tracks, performances and arrangements
- Bibliographic Ontology (BIBO): provides concepts and properties for describing citations and bibliographic references (i.e., quotes, books, articles, etc.)
- Linked Open Vocabularies (LOV): searchable collection of several vocabularies
Linked Data Publishing Patterns
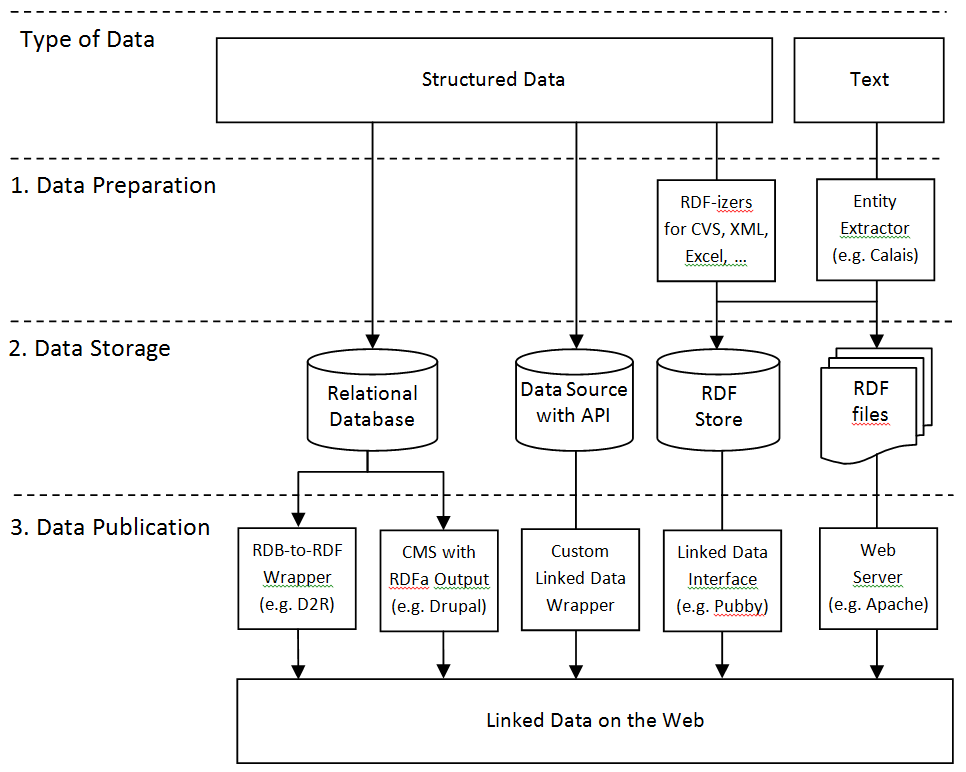
References
- Linked Data: Evolving the Web into a Global Data Space. Tom Heath, Christian Bizer. 2011. pp 1-136. Morgan & Claypool.